I thought Rust already had several different methods for interacting with C++?
Oh? Would you mind sharing them? It would be absolutely fantastic if such a thing existed and is mature enough to be practically used.
All of this user’s content is licensed under CC BY 4.0.
I thought Rust already had several different methods for interacting with C++?
Oh? Would you mind sharing them? It would be absolutely fantastic if such a thing existed and is mature enough to be practically used.
Personally, I have little interest in learning or dealing with C++ solely for the sake of developing KDE applications. I would much rather use Rust.
Imo, restricting the languages that can be used for app development cuts out large swaths of developers who would otherwise be eager to develop software for the project. I’m sure there are some who wouldn’t mind picking up C++ for this cause, but I’d wager that they are a minority. Gnome beats out KDE in that regard, imo, as GTK has bindings and documentation for many languages.
Metaverse in my ass.


That’ll definitely come in handy. Thanks!
without having to reboot to run the installer?
I’m not sure that I understand what you mean. Are you saying that you want to be able to load the OS without having to reboot your computer? Or are you saying that you just don’t want to have to click the equivalent of “try the OS” when booting a live USB? If it’s the latter, you should be able to just select the flash drive as the install point (though, tbc, I have never tried this, but I don’t see why it wouldn’t work) (I think you’d need 2 USBs, though — you’d need 1 to be the installer source, and one to be the install point — I don’t think theres any installer that can run as a desktop application. Though, if it’s Arch Linux, you might actually be able to call pacstrap from the host OS — I’ve never tried this after having already installed the OS). There’s even OS’s that are specifically designed to be ephemeral on hardware in this way — eg Tails OS.

Very clever use case!
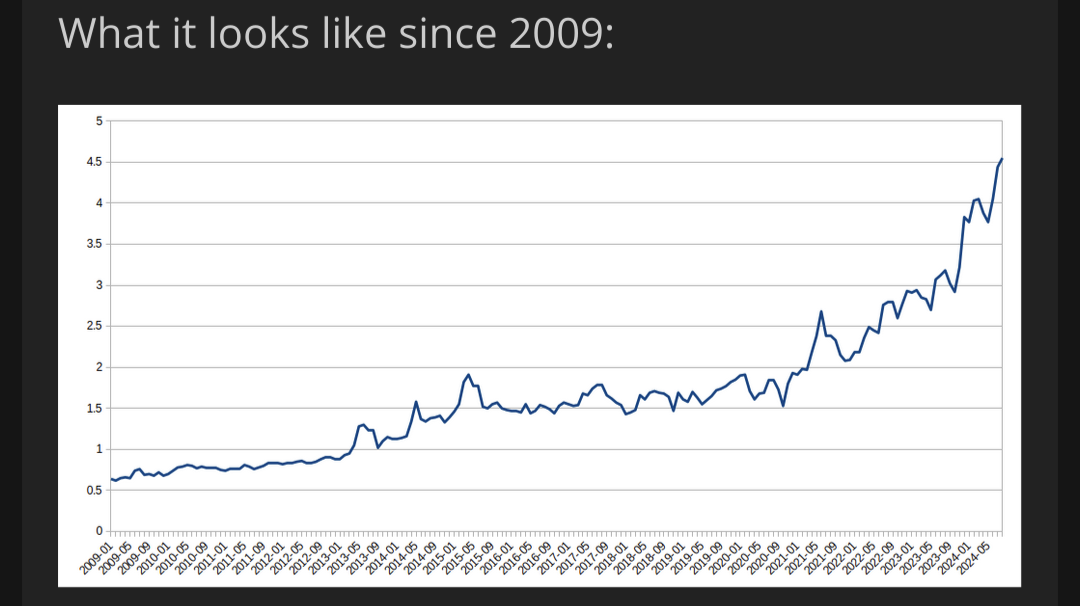
This is amazing! Thank you so much for doing this!! Would you mind telling me your process for extracting the data from the graph? Did you tediously manually extract eye-balled data-points? Or, did you run it through some software which extracted them? Or, perhaps, did you just find and use the original data source?
I’d like to see a logarithmic version of this graph. Picking out a straight line in a log graph is easier than trying to discern an exponential. I want that juicy exponential.
Not really as those are public things.
Would you mind citing an example of exactly what you are referring to? I feel like I’m presuming a lot of things in your statements here.
Dhcp is more of a issue.
I don’t know if it’s “more”, or “less” of an issue, but all these things are worthy of concern.
That would certainly also be worthy of concern.
have the machine pretend you’re in UTC.
That is a possible solution, though not exactly the most convenient, imo. That is, if I understand you correctly that you are talking about setting the OS timezone to be UTC.
could be defeated by doing an analysis of when the commits were made on average vs other folks from random repositories to find the average time of day and then reversing that information into a time zone
This is the first thing I thought of upon reading the title
It’s also in the post body.
Any given time zone there are going to be millions if not billions of people.
One more bit of identifying information is still one more bit of identifying information.
Git also “leaks” your system username and hostname IIRC by default which might be your real name.
This is only part of a fallback if a username and email is not provided [1].
In case (some of) these environment variables are not set, the information is taken from the configuration items
user.nameanduser.email, or, if not present, the environment variable EMAIL, or, if that is not set, system user name and the hostname used for outgoing mail (taken from/etc/mailnameand falling back to the fully qualified hostname when that file does not exist).
A fake name and email would pretty much be sufficient to make any “leaked” time zone information irrelevant.
Perhaps only within the context where one is fine with being completely unidentifiable. But this doesn’t consider the circumstance where a user does want their username to be known, but simply don’t want it to be personally identifiable.
UTC seems like it’s just “HEY LOOK AT ME! I’M TRYING TO HIDE SOMETHING!”
This is a fair argument. Ideally, imo, recording dates for commits would be an optional QoL setting rather than a mandatory one. Better yet, if Git simply recorded UTC by default, this would be much less of an issue overall.
if you sleep like most people, could be defeated by doing an analysis of when the commits were made on average vs other folks from random repositories to find the average time of day and then reversing that information into a time zone.
I mentioned this in my post.
It’s better to be “Jimmy Robinson in Houston Texas” than “John Smith in UTC-0”
That decision is contextually dependent.
How do you mean?

Huh. That’s actually kind’ve a clever use case. I hadn’t considered that. I presume the main obstacle would be the token limit of whatever LLM that one is using (presuming that it was an LLM that was used). Analyzing an entire codebase, ofc, depending on the project, would likely require an enormous amount of tokens that an LLM wouldn’t be able to handle, or it would just be prohibitively expensive. To be clear, that’s not to say that I know that such an LLM doesn’t exist — one very well could — but if one doesn’t, then that would be rationale that i would currently stand behind.
Fair point. I think “leak” is likely the wrong term to use here. “Exposes” is probably a better one. I’ll update the post promptly.
The secret to success: survivorship bias.
I’ve played it for a bit, and it’s a decently fun and well-made game! My only gripe is that it requires an email for signup; I wish it would only require a username and password. For most users, though, I’d wager that that’s a pretty minor issue.






Dang, that’s pretty neat! Man, there’s probably going to be some funky bugs with legacy code getting included into Rust.